%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Generative Models
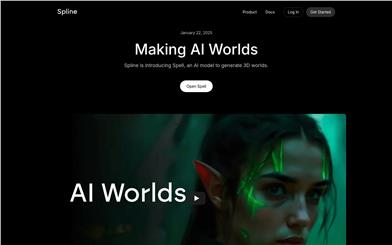
Spell By Spline
Spell is an AI model launched by Spline that can generate complete 3D scenes from a single image. It is based on diffusion model technology and trained by combining real and synthetic data, capable of producing 3D worlds with multi-view consistency in just a few minutes. The major advantage of this technology is its ability to generate high-quality 3D scenes quickly while supporting various rendering techniques such as Gaussian drawing and neural radiance fields. The advent of Spell has brought revolutionary changes to the field of 3D design, allowing creators to generate and explore 3D scenes more efficiently. Currently, Spell is still in development, and the team plans to frequently update the model to enhance quality and consistency.
3D Modeling
51.1K
Eurusprm Stage2
EurusPRM-Stage2 is a cutting-edge reinforcement learning model that optimizes the reasoning process of generative models using implicit process rewards. It calculates process rewards through the log-likelihood ratios of causal language models, improving the reasoning capabilities of the models without incurring additional annotation costs. Its primary advantage lies in its ability to learn process rewards implicitly using only response-level labels, thereby increasing the accuracy and reliability of generative models. The model excels in tasks such as mathematical problem solving, making it suitable for scenarios requiring complex reasoning and decision-making.
Model Training and Deployment
49.1K
Eurusprm Stage1
EurusPRM-Stage1 is part of the PRIME-RL project, which aims to enhance the reasoning capabilities of generative models through implicit process rewards. This model utilizes an implicit reward mechanism that doesn't require the additional labeling of process tags, allowing it to gain rewards during the reasoning process. Its key advantage is its ability to effectively improve the performance of generative models in complex tasks while reducing annotation costs. This model is suitable for scenarios that require complex reasoning and generation abilities, such as solving mathematical problems and generating natural language.
AI Model
47.5K
Flexrag
FlexRAG is a flexible and high-performance framework for Retrieval-Augmented Generation (RAG) tasks. It supports multimodal data, seamless configuration management, and out-of-the-box performance, making it suitable for research and prototyping. Written in Python, it combines lightweight design with high performance, significantly improving the speed of RAG workflows and reducing latency. Key advantages include support for multiple data types, unified configuration management, and ease of integration and extension.
Development & Tools
51.9K
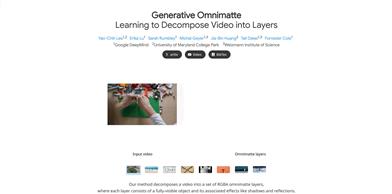
Generative Omnimatte
Generative Omnimatte is an advanced video processing technology that can decompose videos into multiple RGBA layers, with each layer capturing visible objects and their effects, such as shadows and reflections. This technology is significant in video editing and visual effects production, enhancing creative flexibility and efficiency.
Video Editing
48.3K
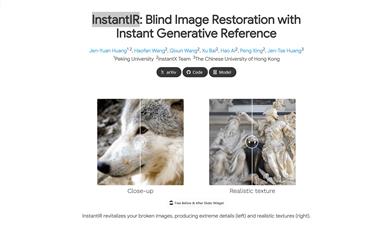
Instantir
InstantIR is a blind image restoration method based on diffusion models that can handle unknown degradation problems during testing, enhancing the model's generalization capabilities. This technology dynamically adjusts generation conditions by generating reference images during inference, thereby providing robust generation conditions. Key advantages of InstantIR include the ability to restore details in extremely degraded images, delivering realistic textures, and enabling creative image restoration through text descriptions. This technology has been jointly developed by researchers from Peking University, the InstantX team, and The Chinese University of Hong Kong, with sponsorship support from HuggingFace and fal.ai.
Image Editing
80.6K
Lfms
Liquid Foundation Models (LFMs) are a series of innovative generative AI models that achieve state-of-the-art performance across various scales while maintaining lower memory usage and higher inference efficiency. LFMs leverage computational units from dynamic systems theory, signal processing, and numerical linear algebra to handle all types of sequential data, including video, audio, text, time series, and signals. These models are general-purpose AI solutions designed to process large-scale, multimodal sequential data, enabling advanced reasoning and reliable decision-making.
Model Training and Deployment
55.2K
Stability AI
Stability AI is a company focused on generative artificial intelligence technology, offering a variety of AI models including text-to-image, video, audio, 3D, and language models. These models are capable of processing complex prompts, producing realistic images and videos, as well as high-quality music and sound effects. The company provides flexible licensing options, including self-hosted licenses and platform APIs, to meet diverse user needs. Stability AI is dedicated to offering high-quality AI services globally through open models.
Image Generation
82.5K
Fresh Picks
SV4D
Stable Video 4D (SV4D) is a generative model based on Stable Video Diffusion (SVD) and Stable Video 3D (SV3D). It takes a single perspective video and generates multiple new perspective videos (4D image matrix) of the same object. The model is trained to generate 40 frames (5 video frames x 8 camera angles) at a resolution of 576x576, given 5 reference frames of the same size. By running SV3D to produce a track video, this track video can then be used as a reference view for SV4D, with the original video serving as reference frames for 4D sampling. The model also generates longer new perspective videos by using the initial generated frame as an anchor point and performing dense sampling (interpolation) for the remaining frames.
AI video generation
63.8K
Fresh Picks
Cookbooks
Cookbooks is an online documentation platform provided by Cohere to guide developers and users in utilizing Cohere's generative AI platform to create diverse applications. It features tutorials for various use cases, including building agents, integrating open-source tools, semantic search, cloud services, retrieval-augmented generation (RAG), and summarization generation. These tutorials offer best practices, enabling users to maximize their use of Cohere's models, and all content is readily available for users to begin testing.
AI Development Assistant
56.0K
GLIGEN
GLIGEN is an open-ended image generation model based on textual prompts, capable of generating images based on textual descriptions and bounding boxes, among other constraints. This model achieves its capability by freezing pre-trained text-to-image Diffusion model parameters and inserting new data within them. Its modular design allows for efficient training and offers strong inferential flexibility. GLIGEN supports conditional image generation in an open world and possesses strong generalization capabilities for new concepts and layouts.
AI image generation
90.3K
SCEPTER
SCEPTER is an open-source code library dedicated to training, tuning, and inference for generative models, covering a range of downstream tasks such as image generation, transfer, and editing. It integrates mainstream implementations from the community as well as independently developed methods from Alibaba's Unisound Lab, offering a comprehensive and general-purpose toolkit for researchers and practitioners in the generative field. This versatile library aims to promote innovation and accelerate the progress of this rapidly evolving field.
AI Model
94.9K

Animatabledreamer
AnimatableDreamer is a framework for generating and reconstructing animatable non-rigid 3D models from single-eye videos. It is capable of creating non-rigid objects of different categories while adhering to the object movement extracted from the video. The key technology is the proposed canonical score distillation method, which simplifies the generation dimension from 4D to 3D, performs denoising across different frames in the video, and carries out the distillation process within a unique canonical space. This ensures consistent generation and realistic morphologies across different postures. With differentiable deformation, AnimatableDreamer elevates the 3D generator to 4D, providing a new perspective on the generation and reconstruction of non-rigid 3D models. Additionally, combining with the inductive knowledge of consistency diffusion models, canonical score distillation can regularize reconstruction from new perspectives, thereby enhancing the generative process in a closed loop. Extensive experiments demonstrate that this method can generate highly flexible 3D models guided by text from single-eye videos, while achieving superior reconstruction performance compared to typical non-rigid reconstruction methods.
AI 3D tools
59.3K
Alloydb AI
AlloyDB AI is a database service introduced by Google Cloud that assists developers in building generative AI applications on top of PostgreSQL. It offers a familiar PostgreSQL interface, supports vector and model management, and can deeply integrate Google Vertex AI for easy access to various generative AI models. AlloyDB AI features enterprise-grade scalability, availability, and security, enabling ultra-high-performance vector operations, making it an ideal choice for building generative AI applications on PostgreSQL.
AI Data Warehouse Query Construction
52.7K
Openai
OpenAI is dedicated to creating safe and beneficial artificial intelligence. Through research in generative models and alignment with human values, we are pioneering the path towards responsible AI. Our products, including ChatGPT and GPT-4D, empower individuals and businesses to harness the transformative power of AI in work and creativity. Our API platform enables developers to leverage cutting-edge models while adhering to best practices for safety and security. Join us in shaping the future of technology.
AI Content Generation
1.1M
Featured AI Tools
Chinese Picks

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
145.7K
Fresh Picks

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
111.0K
English Picks

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
127.5K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
99.1K
English Picks

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
63.8K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
89.1K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
660.5K
Chinese Picks

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M